
در مقاله قبلی به معرفی جداول Memory-Optimized پرداختیم و در اینجا به صورت خلاصه، مهم ترین ویژگی های این جداول را یادآوری می نماییم:
- رکوردهای جداول Memory-Optimized از حافظه Ram خوانده شده و یا روی حافظه Ram نوشته می شوند.
- ساختار خود جدول نیز در حافظه Ram قرار می گیرد (علت این موضوع نیز سرعت بالاتر پردازش حافظه نسبت به Hard Disk است که عملیات I/O خواهد داشت)
- کنترل همزمانی با استفاده از مکانیزم ورژن بندی رکوردها صورت می گیرد تا عملیات Block شدن رکوردها صورت نگیرد و در جاهایی که سرعت دریافت و پردازش اطلاعات زیاد است از Performance بالاتری برخوردار باشیم.
- این جداول می توانند با تنظیمات خاصی روی Hard نیز ذخیره شوند و اصطلاحاً Durable Table بشوند.
شکل زیر حالت ویزاردی ساخت یک جدول Memory-Optimized را در محیط نرم افزار SQL Server Management Studio نمایش می دهد:
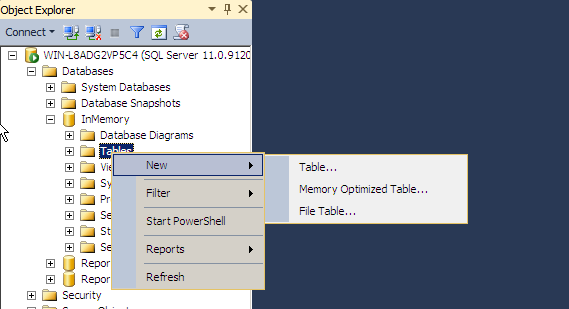
SQL Server در فضای OLTP (یا همان فضای کار با داده های کسب و کارها در زمان اجرای برنامه های عملیاتی) مفهوم جدیدی با عنوان کامپایل Native یا همان Native Compilation را ارائه کرده است. با استفاده از این قابلیت، SQL Server قادر خواهد بود Stored Procedureهایی که با جداول Memory-Optimized کار می کنند را به صورت Native ( یا بومی) کامپایل کند.
کامپایل Native امکان دسترسی سریعتر به اطلاعات و اجرای پرس و جوهای (Query) کارآمدتر را نسبت به کامپایل ( سنتی ) دستورات T-SQL فراهم میکند. خروجی واقعی کامپایل Native نیز، فایل های dll است ( که این فرآیند کاملاً مشابه کامپایل زبان های برنامه نویسی است). جدولهای Memory-Optimized در زمان ساخته شدنشان، کامپایل میشوند، از سوی دیگر SQL Server روالهای Natively Compiled یا همان Natively Compiled Stored Procedureها را در زمان بارگذاری آنها در فایل dll کامپایل می کند. این dllها، هر بار که SQL Server مجدداً راه اندازی شود یا سرور Restart بشود ساخته خواهند شد. البته فراموش نشود که این فایلهای dll بخشی از پایگاهداده نیستند، اگر چه آنها با پایگاهداده در ارتباط هستند و طبیعتاً در فایل های Backup از بانک اطلاعاتی نیز حضور نخواهند داشت.
شیوه ساخت یک جدول Memory-Optimized
برای آنکه در یک بانک اطلاعاتی امکان ساخت این نوع جداول را داشته باشیم، لازم است ابتدا تنظیماتی را روی بانک اطلاعاتی مورد نظر صورت بدهیم. در گام اول لازم است یک Filegroup که شامل memory_optimized_data است را به پایگاه داده خود بیافزاییم و سپس یک فایل ndf را در یک آدرس مورد نظر، به Filegroup ساخته شده اضافه کنیم. به کد زیر توجه کنید:

پس از فعال شدن قابلیت فوق، می توانیم جداول Memory-Optimized مورد نظر خود را با دستور T-SQL اضافه کنیم. دستور زیر جدولی با عنوان InMemoryProduct را به صورت Memory-Optimized Table به بانک اطلاعاتی اضافه می نماید:
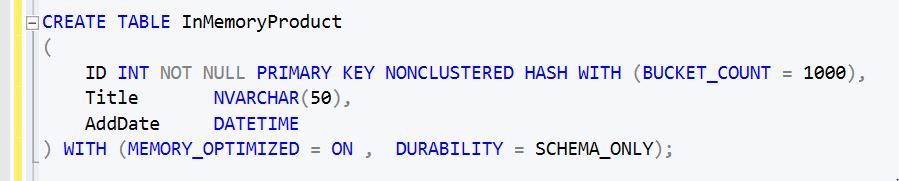
در یک مقایسه کلی از دستورات نوشته شده در نمونه بالا، می توان 3 تغییر کلی با دستور ساخت جداول سنتی (فیزیکی) مشاهده کرد:
- با کلمه کلیدی WITH در انتهای دستور ساخت جدول، کلید و مقدار MEMORY_OPTIMIZED = ON نیز تنظیم شده است و این شاخص، بخش اصلی تعریف جداول Memory-Optimized است.
- در تعریف فوق، کلید اصلی جدول به صورت Non-Clustered تعریف شده است. شاخصی با عنوان BUCKET_COUNT نیز در این بخش تنظیم شده است.
- در بخش دستور WITH کلید DURABILITY نیز با مقدار SCHEMA_ONLY مقداردهی شده است.
بررسی پارامترهای دستور تعریف Memory-Optimized Tableها:
کلید DURABILITY می تواند دو مقدار عمده را دریافت کند که هر کدام، به نوع ذخیره سازی جدول در قالب ذخیره سازی روی Disk اشاره می کنند.
مقدار SCHEMA_ONLY باعث می شود که در صورتی که سرور Restart شود یا حافظه Crash کند، فقط ساختار جدول بازیابی بشود. به بیان دیگر، با این تنظیم، داده های داخل جداول Memory-Optimized قابل بازیابی نخواهند بود و صرفاً از روی Ram خوانده و پردازش می شوند.
مقدار SCHEMA_AND_DATA نیز گزینه دیگری است که می تواند در اینجا مورد استفاده قرار بگیرد. این تنظیم مشخص می کند که این جدول و داده های آن به صورت پایدار روی Disk نیز ذخیره خواهند شد. با این تنظیم، SQL Server هر بار که عملیات I/O را انجام بدهد، تغییرا رکوردها با نسخه قبلی روی حافظه را اعمال می کند تا پایداری جداول ساخته شده روی بانک اطلاعاتی، باقی بماند.
جداول Memory-Optimized معمولاً از ایندکس های Non-Clustered استفاده می کنند که مشابه دستور فوق، شاخصی با عنوان BUCKET_COUNT نیز لازم است تنظیم شود. پیشنهاد Microsoft این است که این شاخص 1.5 الی 2 برابر تعداد رکوردهای منحصر به فرد در جدول باشد. (در مثال فوق فرض بر این است که تعداد محصولات دارای کد منحصر به فرد، حدود 500 محصول باشد)
در مقاله بعدی نیز به معرفی Natively-Compiled Stored Procedure ها خواهیم پرداخت.







